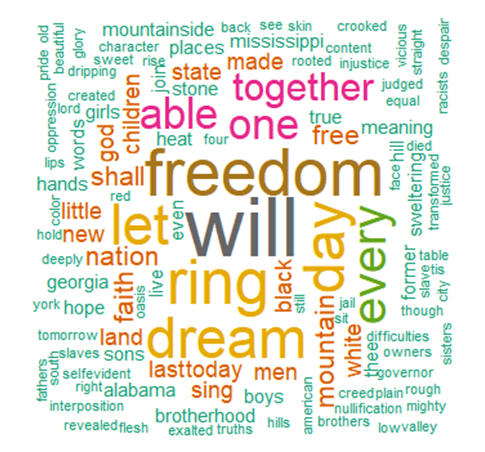
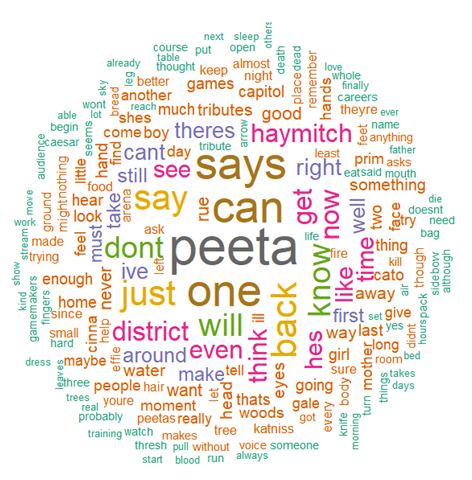
This section is in reference to text mining and word clouds. I have used 2 large data sets for this Martin Luther King’s I Have a Dream speech and a Hunger Games book
Text mining, creating word clouds, and word analysis with two different word populations.
MLK speech
File (.TXT of his speech)
Hunger Games
File (.TXT of book)
Packages and upload
# Load
library("tm")
library("SnowballC")
library("wordcloud")
library("RColorBrewer")
library(Rcpp)
#read in data
text <- readLines(file.choose())
# Load the data as a corpus
docs <- Corpus(VectorSource(text))
Clean data
#inspect(docs)
toSpace <- content_transformer(function (x , pattern ) gsub(pattern, " ", x))
docs <- tm_map(docs, toSpace, "/")
docs <- tm_map(docs, toSpace, "@")
docs <- tm_map(docs, toSpace, "\\|")
# Convert the text to lower case
docs <- tm_map(docs, content_transformer(tolower))
# Remove numbers
docs <- tm_map(docs, removeNumbers)
# Remove english common stopwords
docs <- tm_map(docs, removeWords, stopwords("english"))
# Remove your own stop word
# specify your stopwords as a character vector
docs <- tm_map(docs, removeWords, c("blabla1", "blabla2"))
# Remove punctuations
docs <- tm_map(docs, removePunctuation)
# Eliminate extra white spaces
docs <- tm_map(docs, stripWhitespace)
# Text stemming
# docs <- tm_map(docs, stemDocument)
docs <- tm_map(docs, removeWords, ("and"))
#inspect(docs)
dtm <- TermDocumentMatrix(docs)
m <- as.matrix(dtm)
v <- sort(rowSums(m),decreasing=TRUE)
d <- data.frame(word = names(v),freq=v)
head(d, 20)
tail(d, 20)Build Clouds
set.seed(1234)
wordcloud(words = d$word, freq = d$freq, min.freq = 1,
max.words=200, random.order=FALSE, rot.per=0.35,
colors=brewer.pal(8, "Dark2"))
findFreqTerms(dtm, lowfreq = 4)
findFreqTerms(dtm, lowfreq = 5)
findAssocs(dtm, terms = "district", corlimit = 0.3)
findAssocs(dtm, terms = "but", corlimit = 0.3)
findAssocs(dtm, terms = "thresh", corlimit = 0.3)
head(d, 10)
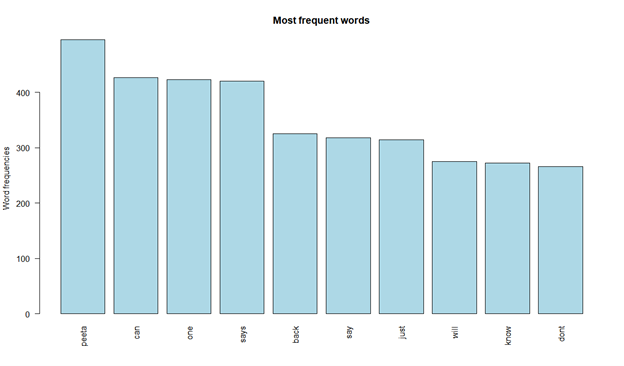
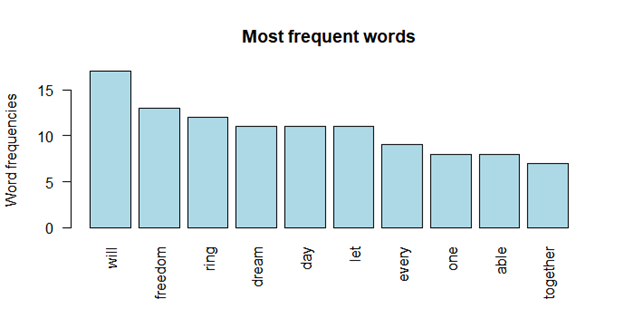
Bar Chart of word frequency
barplot(d[1:10,]$freq, las = 2, names.arg = d[1:10,]$word,
col ="lightblue", main ="Most frequent words",
ylab = "Word frequencies")